
I've been building Kiln AI: an open tool to help you find the best way to run your AI workload. Testing different models to see which ones work best is a huge part of this process.
Here's a sampling of the many different options you need to consider when trying a new model or AI provider:
- JSON & tool calls: Can the model produce structured data? If so, which of the many options are supported, and which works best? (JSON schema, JSON mode, JSON instructions, tool calls, etc)
- Reasoning support: Does the model reason? Does it expose reasoning tokens? Does it have special reasoning syntax we need to parse out like <think>...</think>?
- Use case support: Can it handle specific use cases like synthetic data generation and evals? If so, is it good enough that we'd actually recommend using it?
- Censorship: Will the model refuse to produce certain types of output? This is important for eval data generation where we want to test the model's ability to respond to controversial inputs.
- Provider/host differences: The same model can behave completely differently on different hosts. For example, Ollama does a great job supporting JSON schema with constrained decoding (forcing valid JSON output), but the same model on AWS or Fireworks may produce tons of JSON errors.
- Many more important differences: Does it expose logprobs (confidence scores for each token)? Does it require special directives (like Qwen's /no_think)? What quantizations are supported and should you avoid some? Is it fine-tunable (and how)? Plus many more.
How a focus on usability turned into over 2000 test cases
I wanted things to "just work" as much as possible in Kiln. You should be able to run a new model without writing a new API integration, writing a parser, or experimenting with API parameters.
To make it easy to use, we needed reasonable defaults for every major model. That's no small feat when new models pop up every week, and there are dozens of AI providers competing on inference.
The solution: a whole bunch of test cases! 2631 to be exact.
The solution: a whole bunch of test cases! 2631 to be exact, with more added every week. We test every model on every provider across a range of functionality: structured data (JSON/tool calls), plaintext, reasoning, chain of thought, logprobs/G-eval, evals, synthetic data generation, and more. The result of all these tests is a configuration file with up-to-date information about which models/providers support each parameter, capability, and format.
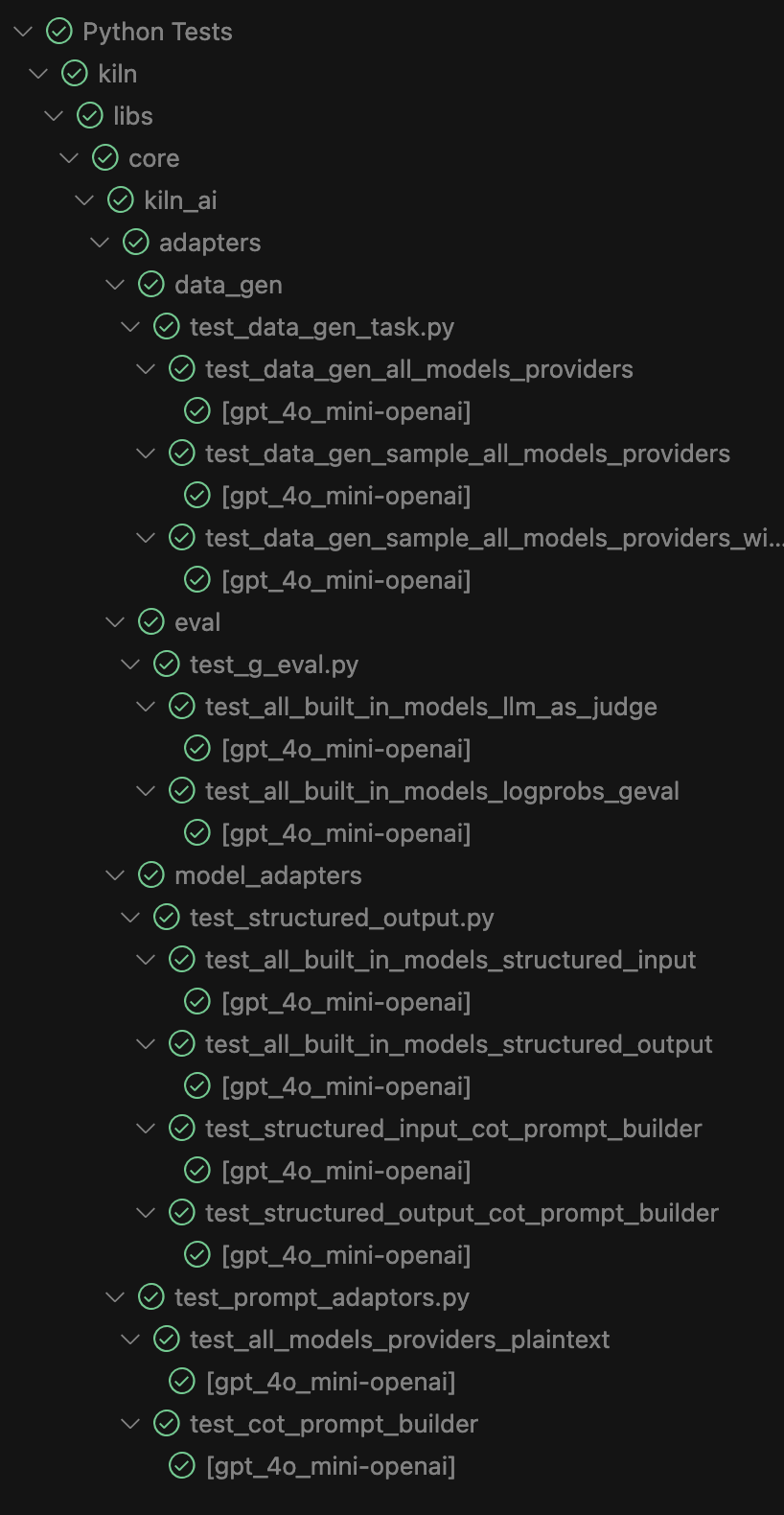
Writing these tests isn't as daunting as it sounds. We use pytest's parameterization feature to iterate over all models and all providers. Each test is actually run on 236 model+provider pairs, so just 11 test cases make up the bulk of the test runs.
Wait, doesn't that cost a lot of money and take forever?
Yes it does! Each time we run these tests, we're making thousands of LLM calls against a wide variety of providers. There's no getting around it: we want to know these features work well on every provider and model. The only way to be sure is to test, test, test. We regularly see providers regress or decommission models, so testing once isn't an option.
However, we do a few things to make this more reasonable:
- We don't run these tests for every commit in CI. Instead we run them about weekly and before each release.
- Once we mark a model/provider as not supporting a feature, we skip that specific test going forward.
- We add a custom pytest marker @paid, so these tests aren't run by default when you run all tests. However, we set up our conftest.py to detect when you're running a single test manually. This makes it easy to use Cursor's UI for testing when working with a new feature or new model.
The Result
The end result is that it's much easier to rapidly evaluate AI models and methods. The model dropdown automatically suggests models/providers that are likely to work for the current task, whether you're running a custom task, creating an eval, or generating fine-tuning dataset.

We don't block models, but we do steer you away from models that are unlikely to work for the current task:
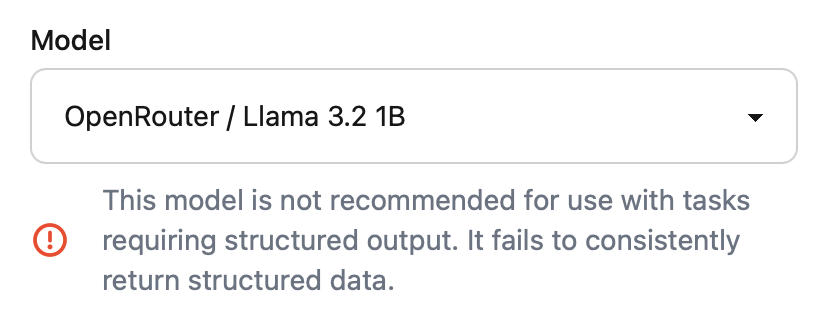
However, you're in control. You can always override any suggestion:

What about LiteLLM and OpenRouter?
Tools like LiteLLM and OpenRouter solve a similar but different problem. They wrap many APIs, allowing you to call various models and providers through a single unified API. We recommend both of them if you need to call many models or multiple AI providers (we use both in Kiln).
However, neither of these recommend parameters for all the various options you'll need when rapidly evaluating different models. Parameters like JSON mode, tool call format, reasoning parsing, etc. That's where the additional Kiln suggestions and parsing come in.
Next steps
This setup is always evolving. Some things I'd like to add:
- ✅ Over the Air Updates: We can now publish improvements over the air, including adding new models as they're released. Automatic updates are disabled by default in our library, but enabled in our app.
- A Giant Ollama Server: I can run a decent sampling of our Ollama tests locally, but I lack the ~1TB of RAM needed to run things like Deepseek R1 or Kimi K2 locally. I'd love an easy-to-use test environment for this.
- Statistical Results: LLM tests are often flaky — a test passes sometimes and fails other times. I'd like to make dozens of calls, get a statistical pass rate (like an eval), and set a minimum threshold. However, this would get exceptionally expensive very fast, so we haven't done it yet.
- More Options: I'd like to bake in more suggested defaults like the model creator's suggested temperature and top_p. However, this gets complex quickly as some suggest a range of values (example from deepseek).
Use Kiln to Find the Best Way to Run Your AI Workload
All of this testing infrastructure exists to serve one goal: making it easier for you to find the best AI solution for your specific use case. The 2000+ test cases ensure that when you use Kiln, you get reliable recommendations and seamless model switching without the trial-and-error process.
Kiln is a free open tool for finding the best way to build your AI system. You can rapidly compare models, providers, prompts, parameters and even fine-tunes to get the optimal system for your use case — all backed by the extensive testing described above.
Just follow our guides:
- Get started: Define your task. What does your AI system do? What format is your data?
- Try it out: Rapidly experiment with various models in the playground. Try over 50 models, 12 AI providers, a variety of prompt templates, and custom prompts. This includes the smart model suggestions above!
- Create an Eval: We'll help you find the best way of running your workload in a rigorous and repeatable way with evals. Kiln will help you build evals from start to finish, including synthetic eval data generation, human baselining, and comparing multiple models/methods.
- Iterate on your product: You can keep using Kiln to stay current as new models come out and your product goals shift. Add new evals as issues are found, ensure you don't regress on prior concerns, and experiment with new models as they launch.
- Go deep with fine-tuning: Need even more performance than off-the-shelf models can give you? Kiln will help you fine-tune faster, smaller and cheaper models. Kiln walks you through synthetic training data generation and tuning both open and closed models.
