
In this video we walk through creating an AI project from start to finish with Kiln. In this video we cover:
- Creating an eval including generating synthetic eval data, creating LLM-as-judge evals, and validating the eval with human ratings
- Finding the best way to run your task by evaluating prompt/model pairs
- Fine-tuning models including synthetic training data and evaluating tunes
- Iterating as project evolves: new evals and prompts
- Set up collaboration with git & GitHub
The project we create in this video is open source on GitHub. You can download the project and try it out yourself.
Video Walkthrough
Preview of Findings from this Demo Project
For the demo project we built a natural language to ffmpeg command builder. Inspired by other projects like this one. Some interesting findings were:
- Adding the
manpage of ffmpeg to the LLM-as-judge model produced the most effective eval - Fine-tuning could boost performance significantly (21% over the base model), but it didn't end up being needed because...
- GPT-4.1 outperformed all other models for this task, even Sonnet 4 and fine-tunes. Don't use LMArena-style evals to predict domain-specific performance.
- Initial high eval scores were tempered by bugs, e.g. the model would happily delete your entire hard drive. We needed to iterate on a set of "product"/"domain" evals to make it into a better product.
Walkthrough
To use this boilerplate:
- To set up the same stack (evals, synth data, tuning), but for your own project/task: download the Kiln app, follow along the steps below, creating your own task in step 1
- To try the demo project from the video: download this repository, and import the
end_to_end_project_demo/project.kilnfile into the Kiln app.
Creating our task
First we set up the task, by defining a title, initial prompt, and the input/output schema.
Creating a "Correctness" eval
The most important feature of the system is that it generates the correct results, so we started by building a correctness eval. This process involved:
- Creating an eval with a name and prompt
- Generating synthetic eval data. 80% for the eval set, and 20% for a golden eval set.
- I manually labeled the golden dataset, so we could check if the LLM-as-Judge evals in Kiln actually aligned with human judgement. This is used to calculate the correlation between LLM-as-judge systems and human evaluators using a range of correlation scores (Kendall Tau, Spearman, MSE)
- I iterated on judges, trying different prompts and models for the judge until I found one that worked well. I got a big jump in judge performance when I added the entire man page for ffmpeg to the judge prompt, and that ended up being the best judge.
See details:
Finding the best way to run your task
With a correctness eval in hand, it was easy to try a variety of prompts and models to see what works best. I tried about a dozen combinations, which you can see in the video and demo files.
Some insights from the experimentation:
- My one-shot prompt did better than the many-shot prompt from the WTFFmpeg project for most models, but their prompt was optimal for the Phi-3 5.6B
- GPT-4.1 (full, mini and nano) really dominated from the start. I would have expected more from Sonnet 4, but GPT-4.1 models just seem better at this task.
Details:
Fine-Tuning
Next we tried fine-tuning 13 models for this task. This involved building a training data set using synthetic data, then dispatching fine-tune jobs. We tried:
- Various base models: Llama, Qwen, Gemini, GPT-4.1
- Various fine-tuning providers: Fireworks, Together, OpenAI, Google Vertex. Note: we didn't do local, but that's also possible.
- A range of parameters: we varied epochs, lora-rank, learning rate.
There were some promising results in the batch (16% and 21% gains in evals over the base model), but I'd experiment more before picking a winner.
Here's a quick glance at the fine-tuning loss from the demo project. When you fine-tune your own project with Kiln, metrics are logged into your Weights and Biases account:
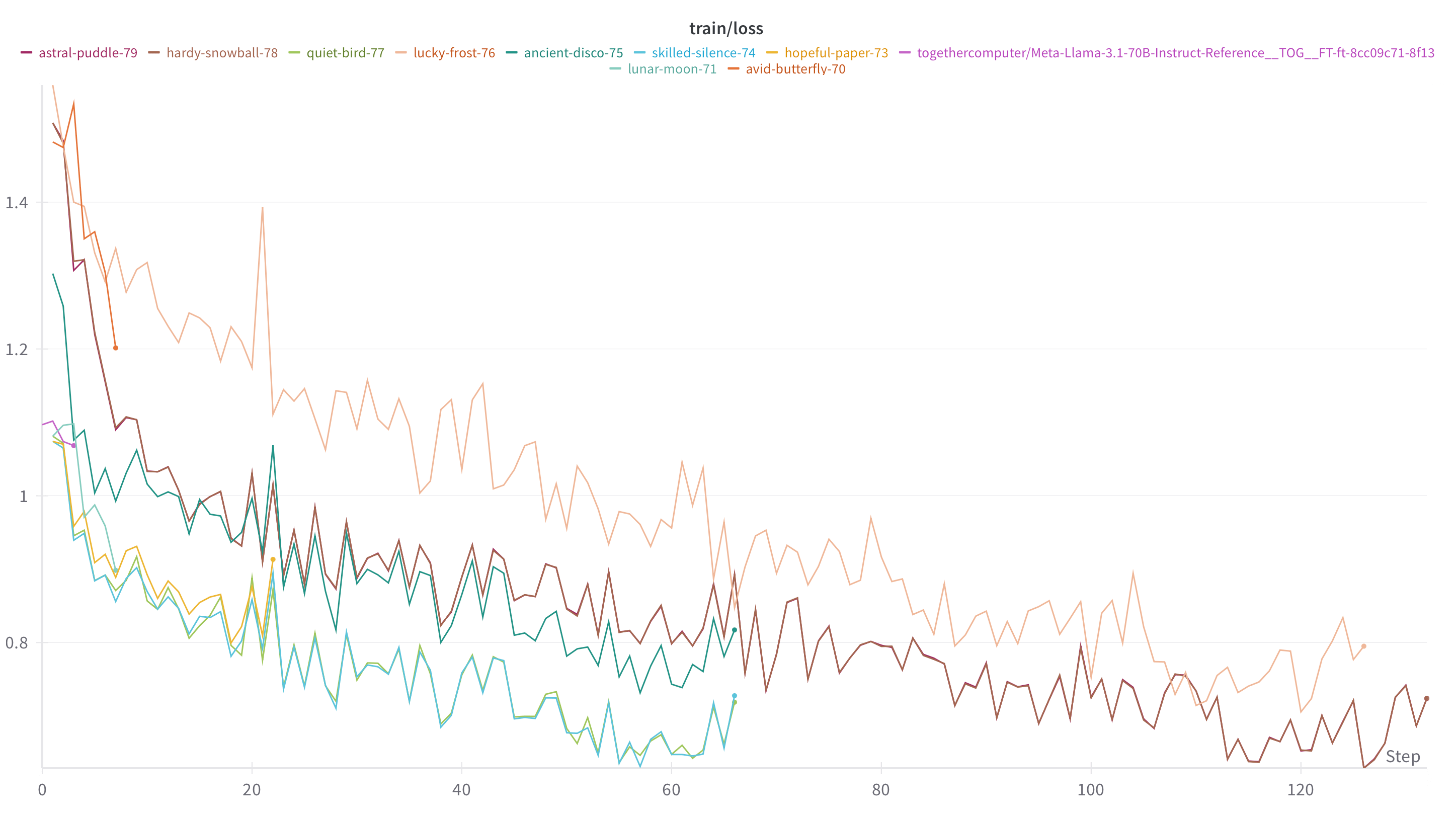
Details:
Iterating as Project Evolves
Next we walk through some examples of iterating on the project:
- A case of fixing a bug we discovered in the system: the model will delete every file on your hard drive if you ask it to. We create a new eval ensuring the generated commands are not destructive, and then iterate on prompts to prevent this from happening.
- Using evals to find tradeoffs between concerns. In this demo we found instruction following went down as we got more prescriptive about things like destructive edits. This makes sense, but we'd have to confirm we want that tradeoff.
- Adding more evals representing product goals: don't recommend competitors, technical preferences (prefer mp4 container), etc
Details:
Setting Up Git Collaboration
Next we sync the project to GitHub, allowing a team to collaborate with familiar synchronization tools and git history.
Details:
Python Library
We only used the Kiln app for this project, but in the video we briefly introduce the Kiln python library which you can use to work with Kiln project in code.
Recap, Docs and Discord
Next Steps
This was a quick demo of all the pieces working together. If I wanted to continue to iterate on quality, here's where I'd focus next:
Improve the Existing Eval
I'm really not sure my manual labels are correct in the golden dataset (I'm not much of a ffmpeg wizard as I thought). More eval data (golden and eval_set), and more iteration on the judge prompt, and better labels from an actual ffmpeg expert would be a good place to invest.
Iteration on model+prompt
I'd iterate more trying to find the best method of running the task, including:
- Try more thinking models, and chain-of-thought on non-thinking models. Building command line parameters seems ideal for step-by-step thinking.
- Try more prompts: try few-shot prompts, try adding some key knowledge to the prompt (for web videos include "-movflags +faststart", "prefer mp4 container if not specified", etc)
Iterate on product side with evals/prompts
Each model has its own style of output; they swap the order of the explanation/command and the formatting. I'd want to define the best version, and write some evals to confirm they follow it.
More Fine-Tuning: only if local or cost optimization was the goal
I probably wouldn't iterate on fine-tuning unless I really wanted a system that could run locally or to really reduce price per token.
Why? The foundation models work pretty damn well. They seem to already have good knowledge about how to use ffmpeg. Iterating on prompting would probably be faster and more effective than fine-tuning. Fine-tuning can be great when cost/privacy are critical, but it's a lot of extra work and will slow your project down.
If I wanted a system that could run locally or to really reduce price per token, fine-tuning would help. The high quality models either closed/hosted (GPT 4.1, Sonnet) or too big for the average person to run locally (Qwen 3 32B/Llama 70B).
Our quick pass at fine-tuning has shown it can really improve the performance of smaller models; in particular Llama 3B and Gemini Flash saw big jumps. To iterate I'd try:
- Generate a larger training set. I started with 330 examples, then added 719 more and could see a benefit. To do this I'd probably manually build a list of all ffmpeg features and use that as top-level topics for synthetic data generation that would let me systematically ensure every feature was contained in the training dataset. I'd also look around for existing examples to include.
- I'd try more base models like Gemma, Llama 3.1, Qwen. We've already seen that there's a wide quality gap between models (likely from their pre-training data). The right base model could boost quality, although as the training set got better I'd imagine the gap closes.
- I'd try smaller models. I'd bet with the right training data, even a 1B parameter model could do well given how constrained this problem is.
Using the AI Task we Created
This was built as a demo project, not a real product. However I've actually found it handy. I used it to re-encode the video walkthrough before uploading it to Vimeo, and it did things I wouldn't have thought of like using a lanczos scaler to keep sharper text (since I told it that the content was a screencast). You can see the commit here. Kinda cool!
If any ffmpeg wizard wants to take a stab at improving the performance with new evals/prompts/tunes, I'd be happy to take PRs.
Get Kiln to Make Your Own Project
Kiln is a free open tool for finding the best way to build your AI system. You can rapidly compare models, providers, prompts, parameters and even fine-tunes to get the optimal system for your use case.
